[ELMA3] Рекомендации по обслуживанию и настройке серверов MSSQL Server
Данная статья содержит в себе следующую информацию:
- Обновление экземпляра MSSQL Server.
- Плановые работы по обслуживанию индексов (реорганизация/перестроение) и обновлению статистики.
- Советы по тонкой настройке и оптимизации баз данных MSSQL Server. (Установка, первичная настройка, шринк лога транзакций).
- Работа со счетчиками производительности Performance Counter для выявления и устранения проблем, связанных с производительностью экземпляра сервера.
1. Обновление экземпляра MSSQL Server
Необходимо постоянно контролировать и обновлять экземпляр MSSQL Server для закрытия уязвимостей и обновления движка Database Engine. Для этого необходимо выполнить ряд действий.
1. Уточнить установленную редакцию и версию экземпляра сервера, установленного у нас:

2. Перейти на сайт https://technet.microsoft.com/ru-ru/sqlserver/ff803383.aspx и просмотреть доступные обновления для установленной версии экземпляра сервера. В большей степени нас интересуют:
- Latest Service Pack;
- Latest Cumulative Update.
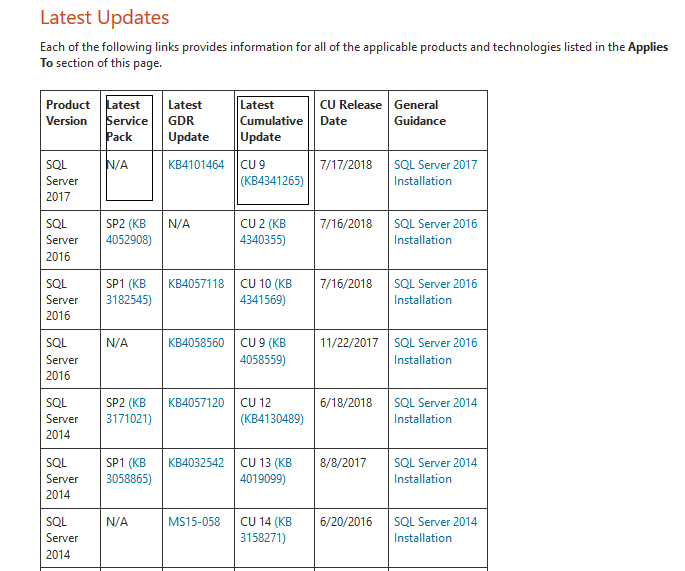
3. Если таковые доступны, то необходимо скачать и установить их. Процесс установки стандартный: требуется запустить exe-файл и установить обновления для выбранного экземпляра MSSQL Server.
2. Плановые работы по обслуживанию индексов (реорганизация/перестроение) и обновлению статистики
Для поддержания производительности Базы данных необходимо проводить плановую периодическую реорганизацию/перестроение индексов. В противном случае можно получить "performance degradation" (падение производительности) для базы в целом.
Для начала необходимо проверить наличие и степень фрагментации индексов в используемой базе. Для этого требуется выполнить следующий код:
USE ELMA_SOURCE
SELECT s.[name] +'.'+t.[name] AS table_name
,i.NAME AS index_name
,index_type_desc
,ROUND(avg_fragmentation_in_percent,2) AS avg_fragmentation_in_percent
,record_count AS table_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ips
INNER JOIN sys.tables t on t.[object_id] = ips.[object_id]
INNER JOIN sys.schemas s on t.[schema_id] = s.[schema_id]
INNER JOIN sys.indexes i ON (ips.object_id = i.object_id) AND (ips.index_id = i.index_id)
ORDER BY avg_fragmentation_in_percent DESC
Результат выполнения кода представлен на рисунке ниже:
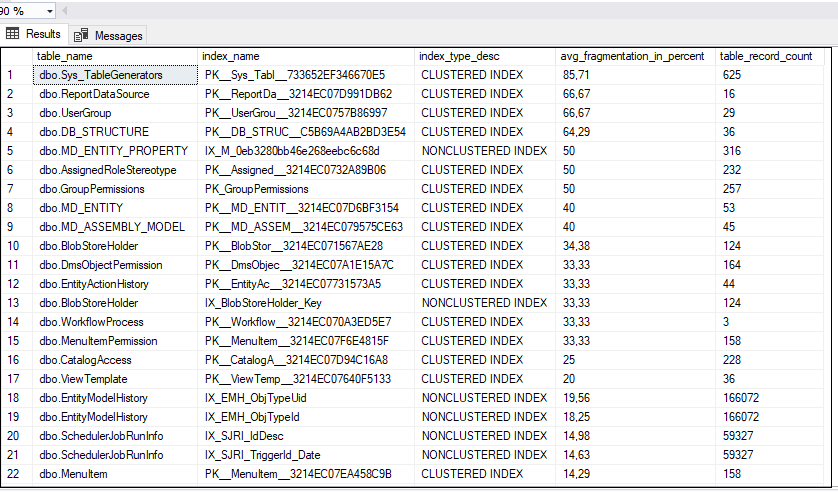
Где: table_name – имя таблицы, index_name – имя индекса, index_type_desc – тип индекса, avg-fragmentation_in_percent – степень фрагментации индекса, table_record_count – количество записей в таблице.
В первую очередь следует обращать внимание на индексы, где степень фрагментации выше 15%. Для индексов степень фрагментаций которых от 15 до 30% необходимо выполнять реорганизацию, а для индексов, где степень фрагментации свыше 30% - выполнять перестроение. Индексы со степенью фрагментации от 0-15% являются нормальными. Также нужно учитывать, что даже после проведения процедур по реорганизации/перестроению индексов степень фрагментации некоторых индексов может также остаться выше нормы. В основном это бывает для индексов, расположенных в таблицах с небольшим количеством записей (до 1000 строк).
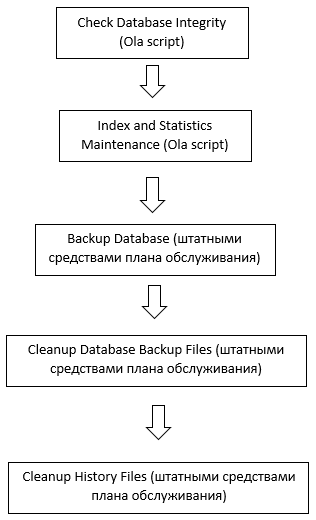
Дальше следует на постоянной основе обслуживать индексы и следить за их фрагментацией. В этом случае можно воспользоваться штатными средствами MSSQL Server (Создать план обслуживания – доступен для редакций Standart, Enterprise, но недоступен для редакции Express). Создать план обслуживания с необходимыми задачами по проверке целостности базы и реорганизации/перестроению индексов, там же назначить время и периодичность выполнения для данных задач.
Также можно воспользоваться прекрасным средством – скриптами https://ola.hallengren.com/, получившими мировое признание и использующимися большинством DBA в своей повседневной работе по обслуживанию БД. Для этого необходимо:
1. Скачать с официально сайта необходимый нам скрипт.
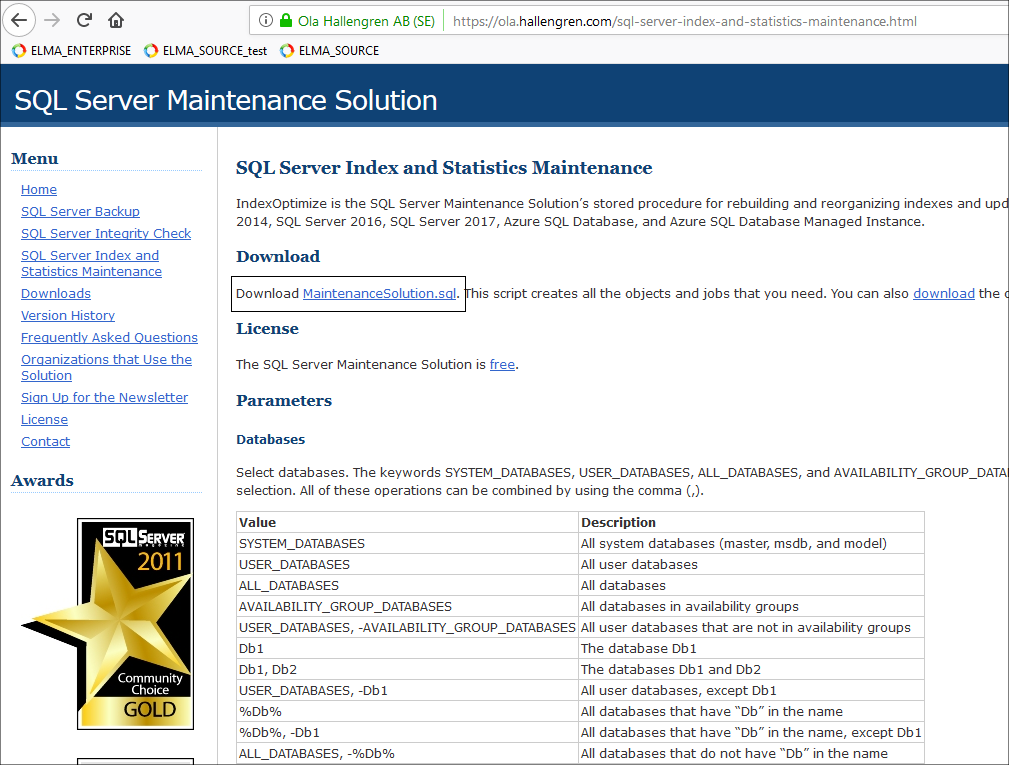
2. После скачивания запустить его и выполнить в среде Management Studio. Скрипт инициализируется и создает несколько необходимых нам хранимых процедур.
После этого нам остается настроить необходимые нам "джобы" (job – задание) и поставить в них время выполнения и периодичность, либо создать план обслуживания, в котором указать созданные джобы.
Скрипты ola.hallengren.com позволяют автоматизировать процесс реорганизации/перестроения индексов. При этом при выполнении задания автоматически проверяется степень фрагментации индексов: если она составляет 15-30%, делается реорганизация; если больше 30%, то перестроение (при этом регулируется нагрузка на БД).
Также с помощью уже других скриптов можно проверять целостность базы данных, а также настраивать автоматическое резервное копирование, что тоже очень полезно и просто необходимо!!! Все параметры можно гибко конфигурировать в самом скрипте.
Ниже приведен небольшой пример создания задания.
Создаем Job (задание) в MSSQL Server.
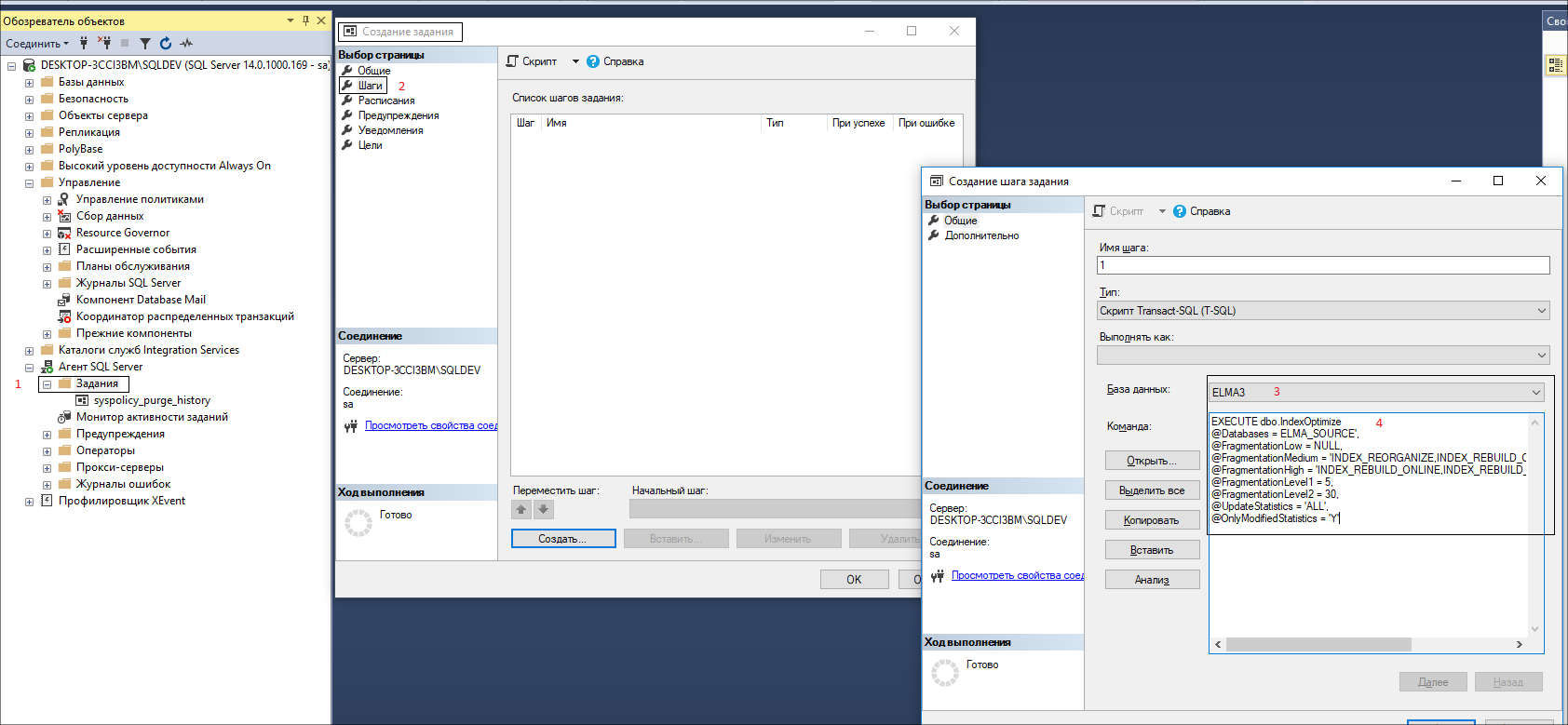
Мы создали задание и написали скрипт для реорганизации/перестроения индексов.
EXECUTE dbo.IndexOptimize
@Databases = 'ELMA_SOURCE',
@FragmentationLow = NULL,
@FragmentationMedium = 'INDEX_REORGANIZE,INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE',
@FragmentationHigh = 'INDEX_REBUILD_ONLINE,INDEX_REBUILD_OFFLINE',
@FragmentationLevel1 = 5,
@FragmentationLevel2 = 30,
@UpdateStatistics = 'ALL',
@OnlyModifiedStatistics = 'Y'
EXECUTE dbo.DatabaseIntegrityCheck
@Databases = 'ELMA_SOURCE',
@CheckCommands = 'CHECKDB'То же самое можно написать для проверки целостности базы данных.
То же самое можно сделать и для резервного копирования. Примеры скриптов доступны на сайте ola.hallengren.com. После этого необходимо запустить задание, поставить для него время и периодичность выполнения, либо использовать план обслуживания, где выбирать созданные задания и сохранить их. Например, может быть использован следующий план, созданный с помощью плана обслуживания еженедельно по воскресеньям.
3. Советы по тонкой настройке и оптимизации баз данных MSSQL Server
В процессе установки экземпляра MSSQL Server необходимо устанавливать только те компоненты, которые действительно необходимы. Здесь можно действовать по принципу – чем меньше, тем лучше, недостающие компоненты всегда можно установить дополнительно.
Путь к папке с экземпляром сервера требуется оставлять по умолчанию, как и место хранения системных баз данных (master, model, msdb). Например:
С:\Program Files\Microsoft SQL Server\MSSQL14.SQLEXPRESS\MSSQL\DATA\
где папка MSSQL14.SQLEXPRESS является папкой экземпляра сервера.
Пользовательские базы данных необходимо переносить на другой диск. Хорошим тоном является создание 3 логических дисков, на каждом из которых помещается основной файл базы данных, на другом – файл журнала транзакций, на 3 – база данных tempDB.
Если позволяют системные ресурсы, в идеальной ситуации файл базы данных, журнал транзакций и база данных tempDB должны находится на разных физических дисках для увеличения производительности.
Для самого экземпляра MSSQL Server по возможности следует выделять отдельный сервер! Либо, если используется виртуализация, выделять отдельную виртуальную машину.
У установленного экземпляра MSSQL Server в настройках сервера обычно задается предел Maximum server memory, а не оставляется динамическое значение по умолчанию. Например, если сервер выделен под экземпляр MSSQL Server и на нем установлено 32 Гб оперативной памяти, можно поставить фиксированное значение в 30 Гб и 2 Гб оставить под операционную систему с антивирусными программами.
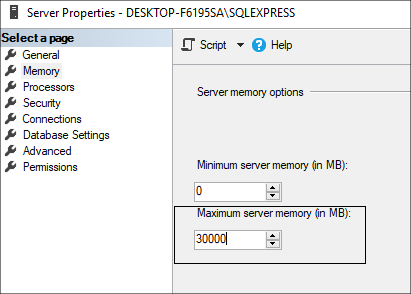
Также необходимо обязательно следить за тем, чтобы в настройках Базы данных была отключена опция Автоматического сжатия файла базы данных (Auto Shrink), которая может оказать серьезное воздействие на производительность базы в целом.
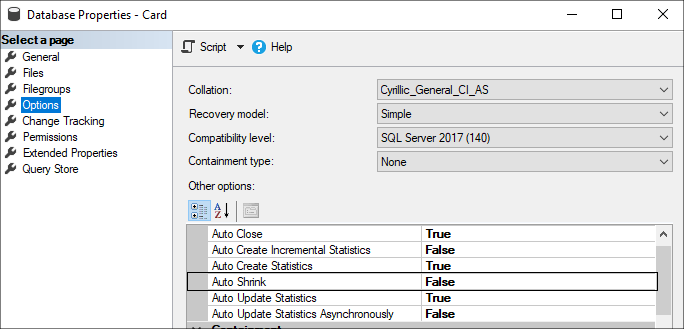
Также необходимо контролировать лог журнала транзакций, который, в свою очередь, может оказывать воздействие на падение производительности. Когда размер журнала транзакций больше размера файла данных, это уже плохо и нужно предпринимать меры.
Любой журнал транзакций содержит в себе файлы виртуальных журналов транзакций, так называемые VLF. Чем больше VLF, тем хуже для журнала транзакций. По «Best Practice» количество VLF не должно превышать 50. В случае, если журналы транзакций превышает 1000 и более VLF необходимо предпринимать меры для уменьшения и последующего поддержания виртуальных файлов журналов транзакций в норме, не допуская выхода за границы. Посмотреть текущее количество файлов виртуальных журналов транзакций можно командой DBCC LOGINFO.
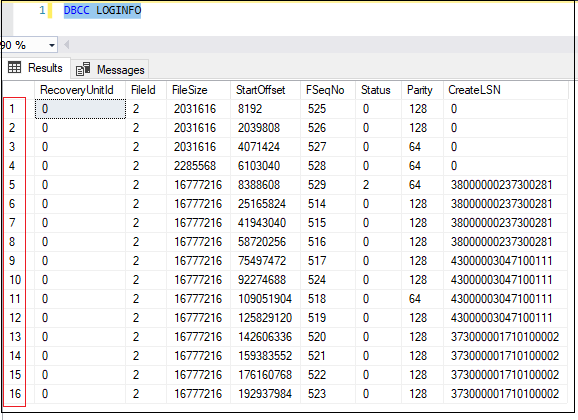
Причиной также может быть маленький размер автоприращения файла лога журнала транзакций, вследствие чего при записи данных в лог журнала транзакций создаются новые порции виртуальных журналов транзакций. Изменить размер автоприращения можно в свойствах базы данных на вкладке Файлы.
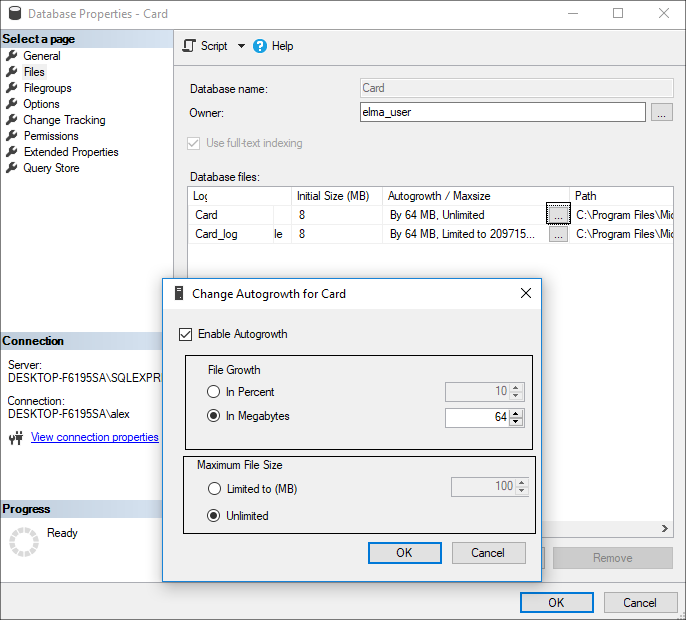
Либо Transact SQL инструкциями:
--Блок инструкций 1--
Use ELMA_SOURCE
GO
DBCC LOGINFO
--Блок инструкций 2--
BACKUP LOG ELMA_SOURCE TO DISK = 'D:\test\ELMA_SOURCE_backup_log.trn'
GO
DBCC LOGINFO
--Блок инструкций 3--
DBCC SHRINKFILE (ELMA_log, 1)
GO
DBCC LOGINFO
--Блок инструкций 4--
ALTER DATABASE ELMA_SOURCE
MODIFY FILE
(
NAME = ELMA_SOURCE_log,
FILEGROWTH = 1000
)
GO
DBCC LOGINFOВ данном случае задано приращение в 1 ГБ. Также приращения и размеры лучше задавать предельным значением, а не процентами.
4. Работа со счетчиками производительности Performance Counter для выявления и устранения проблем, связанных с производительностью экземпляра сервера
Одну из главных ролей стабильной работы MSSQL сервера является постоянный мониторинг и выявление причин падения производительности (performance degradation) и поиска узких мест (bottlenecks). В решении этих проблем помогают счетчики производительности Performance Counter (доступны по умолчанию в Windows). Счетчики производительности позволяют собирать информацию в виде графиков с историей хранения значений, позволяют отслеживать значения в режиме реального времени, а также смотреть историю значений, делать сопоставления, возвращаться к архивным данным. Для более удобной работы со счетчиками производительности можно использовать сторонние системы мониторинга, например, Zabbix.
Стандартные счетчики Windows доступны по умолчанию и помогают отслеживать такие важные показатели, как загрузку процессора, использование памяти и загрузку дисковой системы, своевременно выявлять узкие места в работе сервера. При установке экземпляра MSSQL Server также добавляются специализированные счетчики MSSQL Server, необходимые для мониторинга самого MSSQL Server.
Посмотрим на примере.
Добавляем необходимые счетчики для отслеживания.
В данном случае они выглядят так: системные + счетчики MSSQL Server. В идеальном случае нужно, чтобы счетчики отображались по-английски, все названия, рекомендованные значения – тоже представлены на английском языке. Русские названия могут вызвать путаницу.
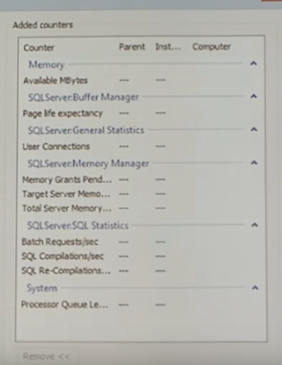
Ниже приведены «Best Practice» счетчиков производительности, которые были использованы для мониторинга систем:
|
Memory |
|
|
Available Mbytes |
Свободная память в мегабайтах. Когда данный счетчик показывает значение меньше 200 Мегабайт, нужно задуматься о том, что есть проблемы с памятью. |
|
Physical Disk |
|
|
Avg.Disc sec/Read _Total Avg.Disc sec/Write _Total |
Счетчик производительности PhysicalDisk(_Total) \Avg. Disk sec/Read (Время в секундах, в среднем затрачиваемое на одну операцию чтения данных с диска. Показывает среднее время выполнения операции чтения с диска). Предельно допустимые значения не должны превышать 15-20 Миллисекунд. Счетчик производительности PhysicalDisk(_Total) \Avg. Disk sec/Write (Среднее время записи на диск в секундах — это время, в среднем затрачиваемое на одну операцию записи данных на диск). Предельно допустимые значения не должны превышать 15-20 Миллисекунд. |
|
Processor |
|
|
%Processor Time _Total %Processor Time 0 %Processor Time 1 %Processor Time 2 %Processor Time 3 |
Среднее время загрузки процессора (как в общем, так и по ядрам в отдельности). Смотрим, на сколько загружен у нас процессор, и определяем, является ли он узким местом в работе всего сервера. |
|
SQLServer Buffer Manager |
|
|
Page life expectancy Buffer Cache Hit Ratio |
Счетчик производительности SQL Server: Buffer Manager: Buffer Cache hit ratio (Доля страниц, обнаруженных в буферном кэше без чтения с диска). Эталонное значение > 90 (опять же указывает на проблемы с памятью). Счетчик производительности SQL Server: Buffer Manager: Page life expectancy (указывает среднее время жизни страниц в буферном кэше). Чем больше, тем лучше. Предельное значение – 300. PLE именно тот счетчик, за которым надо следить, но его показания имеют смысл, если они падают значительно ниже нормы (< 300) и остаются долго в таком положении (опять же указывает на проблемы с памятью). |
|
SQLServer General Statistics |
|
|
User Connections |
Количество пользователей, подключенных в данный момент к серверу MSSQL Server. |
|
SQLServer Memory Manager |
|
|
Memory Grants Pending Target Server Memory Total Server Memory |
Total Server Memory – данные счетчика предоставляют информацию об объеме памяти, выделенной серверу диспетчером памяти. Target Server Memory – данные счетчика предоставляют информацию об идеальном объеме памяти, необходимом серверу. Если Total Server Memory меньше Target Server Memory, это является признаком нехватки памяти. |
|
SQLServer SQL Statistics |
|
|
Batch Request/sec SQL Compilations/sec SQL Re-Compilations/sec |
Batch Request/sec – счетчик показывает насколько загружен SQLServer, значение свыше 1000 запросов в секунду к серверу указывает на достаточно загруженную систему. SQL Compilations/sec – компиляций SQL, выполненных за секунду. В идеальном случае должно быть меньше 10% от показаний счетчика Batch Request/sec. SQL Re-Compilations/sec – среднее число рекомпиляций в секунду. Чем меньше значение этой характеристики, тем лучше. В идеальном случае должно быть меньше 10% от показаний счетчика SQL Compilations/sec. |
|
System |
|
|
Processor Queue Length |
Текущая длина очереди процессора, измеряемая числом ожидающих потоков. Все процессоры используют одну общую очередь, в которой потоки ожидают получения циклов процессора. Eсли компьютер имеет несколько процессоров, нужно разделить эту величину на количество процессоров, обслуживающих нагрузку. Постоянное значение > 2, может свидетельствовать о перегруженности процессора. |
Список основных счетчиков производительности и их рекомендованные значения можно посмотреть также на сайте Microsoft, либо в независимых источниках.
После создания и запуска сборщика данных, следует собрать показания счетчиков, параллельно в системном мониторе можно просматривать отчеты по всем счетчикам, либо для лучшего наглядного представления перевести все на систему мониторинга – Zabbix.
Еще одной особенностью и несомненным плюсом является то, что собранные метрики, находящие по пути c:\PerfLogs\Admin\MSSQL Collection\DESKTOP-F6195SA_20180802-000001\Счетчик производительности.blg, можно наложить на собранные трассировки MSSQL Server Profiler. Это дает возможность сопоставить запросы или хранимые процедуры с графической составляющей сборщика данных для понимания того, какие ресурсы использовались и с какой степенью загрузки при выполнении запроса или хранимой процедуры. Выглядит это следующим образом:
